How to build an automated lead enrichment pipeline that runs before your SDR touches a lead
SDRs spend 20 minutes per lead on manual research. Here's the n8n + Claude workflow that enriches leads the moment they enter your CRM.
Your SDRs know what to do. The problem is they spend the first 20 minutes on each lead doing work a computer can do faster and more consistently. LinkedIn, the company website, Google for recent news, back to the CRM to type it all in. By the time they’ve got a picture of who they’re dealing with, the lead is already cooler than it was when it came in.
Three separate posts on r/AIAgentsInAction, r/digital_marketing, and r/CRM in a ten-day window last month described the same pattern. 20 minutes per lead. Multiply that across a five-rep team researching 10 leads each per day, and you’re burning 250 hours a month on prep work before a single email gets written.
This is a solvable problem. The workflow that fixes it runs in 30-60 seconds per lead, costs less than $0.15 per record, and doesn’t require Clay.
The problem: 20 minutes per lead, before outreach even starts
Manual lead research exists because reps need context before they can write a good first email or take a meaningful call. They need to know what the company does, who they’re talking to, whether the company is the right size, whether anything’s happened recently that makes this a good moment to reach out.
Getting that context manually means bouncing between five tabs and typing notes into a CRM field. On a good day it takes 15 minutes. On a bad day, when the company’s website is thin and LinkedIn is behind a login prompt, it takes 30. Most reps do it inconsistently, which means some contacts get full context and others get a cold open with no preparation.
The downstream effect isn’t just wasted time. It’s inconsistency in how leads get handled, depending on which rep picked them up and how much time they had that morning.
Why timing matters more than the tool
Most teams that try to fix this treat it as a batch job. They export a CSV, run it through an enrichment tool, import it back into the CRM, and then wonder why reps still aren’t using the data. Usually it’s because the data arrived before the rep was thinking about the lead, so it got buried. Or it arrived stale, because a week passed between export and import.
The fix isn’t enriching a list. It’s enriching in real time, triggered the moment a lead changes stage.
When a new contact enters your CRM or moves to “New Lead” status, a webhook fires. An n8n workflow runs enrichment immediately. By the time the rep opens the record, the brief is already there. The rep didn’t have to request it, didn’t get it in a separate email, and didn’t have to do any research. It’s sitting in the contact notes and custom fields, written before anyone touched the lead.
That’s the architectural change that makes enrichment data actually get used.
What the workflow does
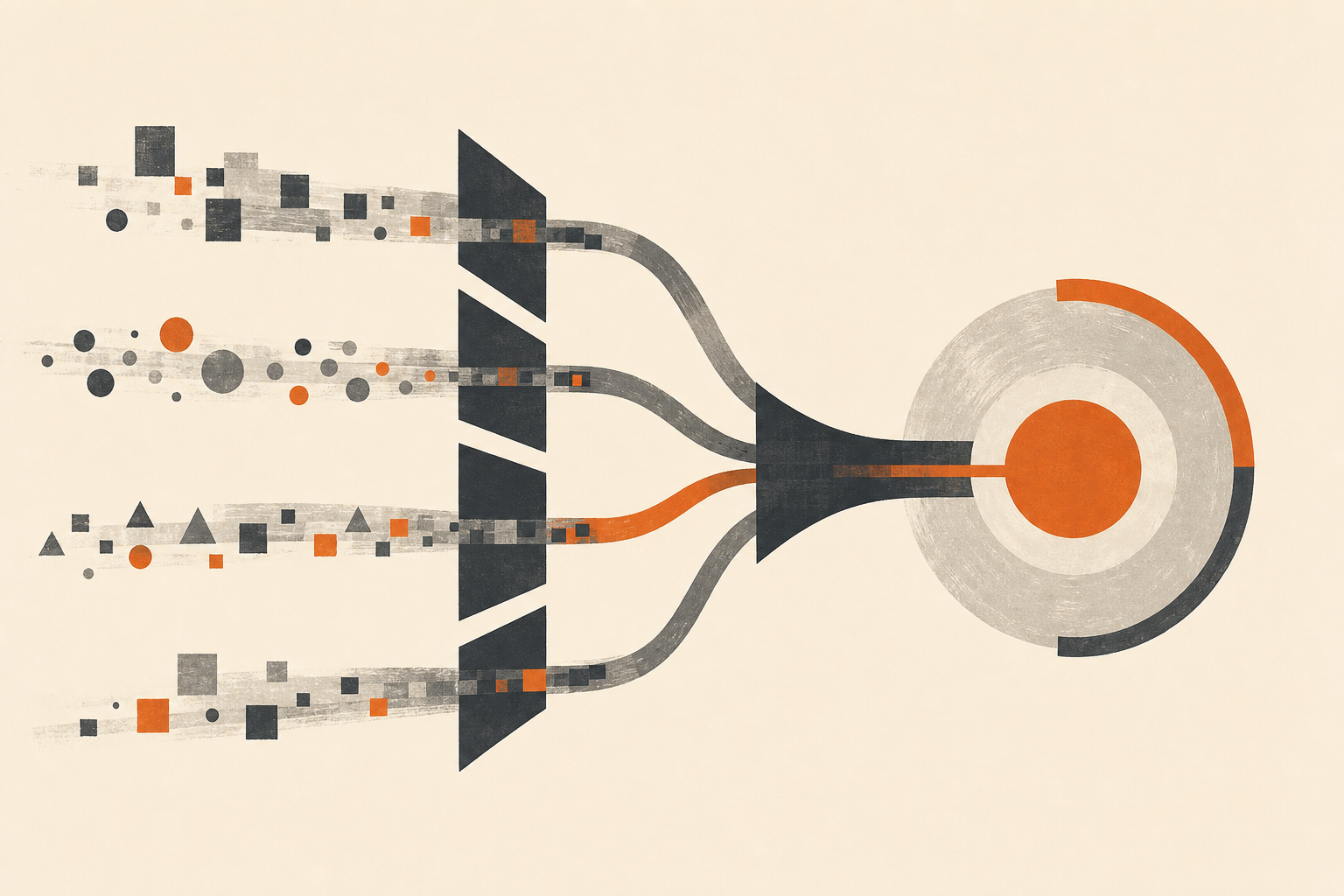
The workflow has five steps: trigger, enrich, score, route, and write back.
Trigger: A HubSpot Deal or Contact workflow fires a webhook when a lead hits a defined stage. In n8n, this lands in a Webhook node. If webhooks aren’t available on your tier, n8n can poll HubSpot every few minutes instead.
Enrich (parallel): Two enrichment calls run simultaneously. People Data Labs (PDL) fetches firmographic and contact data: company name, size, industry, location, title, and work email. Perplexity searches for recent context on the person and the company: funding rounds, leadership changes, and relevant content published in the last 90 days. Running these in parallel cuts processing time roughly in half.
Score: Claude receives the merged profile and your ICP rules, stored in a Google Doc. It scores the lead on four dimensions: company fit (0-3 points), title fit (0-3 points), buying signals like funding or recent hiring (0-2 points), and timing signals (0-2 points). A score of 8-10 is hot. 5-7 is warm. Below 5 is cold. Claude also writes a two-sentence summary of why the lead scores the way it does.
Route: Based on the score, the workflow routes to three paths. Hot leads trigger an immediate Slack alert with the brief and a draft opening line for outreach. Warm leads go into a daily digest. Cold leads get logged to the CRM with no alert.
Write back: For all leads that score 5 or above, the workflow upserts enriched fields back to the HubSpot contact: company size, industry, ICP score, and the Claude-generated brief as a contact note.
flowchart LR
A["HubSpot stage change\nfires webhook"] --> B["PDL: firmographic\n+ contact data"]
A --> C["Perplexity: recent\ncompany activity"]
B --> D["Merge profile"]
C --> D
D --> E["Claude: ICP scoring\n+ brief"]
E --> F{"Score?"}
F -- "8-10 hot" --> G["Slack alert\n+ outreach draft"]
F -- "5-7 warm" --> H["Daily digest"]
F -- "0-4 cold" --> I["CRM log only"]
G --> J["Write back to\nHubSpot fields"]
H --> J
The n8n template #9433 (“Enrich and score leads automatically with Claude AI, PDL and Perplexity”) covers this base architecture. The additions worth making are the HubSpot stage-change trigger, a fallback node for PDL misses, and the field writeback pattern.
The data source question: PDL, Clearbit, or Apollo?
PDL is the default choice because it returns structured data via a clean API and covers most B2B segments well. Cost is roughly $0.03-0.08 per enriched record depending on volume.
PDL misses around 30-40% of records in some segments, particularly professional services and smaller firms. For those, a fallback node that routes to Apollo or Clearbit after a PDL miss keeps coverage high. Apollo’s API returns similar firmographic fields and works as a solid backup.
Clearbit was acquired by HubSpot and is now part of Breeze. If you’re on HubSpot Professional or above, Breeze Enrichment runs natively without a separate API call. It covers company-level data well but is thinner on contact-level enrichment than PDL.
The practical default: PDL with an Apollo fallback for any contact PDL can’t resolve, and Perplexity for the recent-context layer. Perplexity pulls from live web data rather than a static database, which is what gives you the “anything changed recently?” signal that static enrichment misses.
The obvious first approach, and why it fails
A natural first attempt is to let the AI browse freely for context on each lead. Tell Claude to search the web, summarize what it finds, and write a brief. It looks good in demos and fails badly in production.
The problem is that freeform web browsing produces hallucinations. An AI asked to “find recent news about Company X” will sometimes find relevant results and sometimes confidently return invented facts that look plausible. Reps who catch a wrong fact early stop trusting the whole brief. The ones who don’t catch it send outreach based on information that doesn’t exist.
The fix is to source context from structured signals rather than open-ended search. Perplexity is better than raw browsing because it searches current news and prioritizes dated sources. But the most reliable signals are even more structured: job change APIs (person moved to a new role at a target account), funding databases (company raised a round), and published content that’s definitively linked to the company. When the AI drafts off a specific verifiable signal, the brief is grounded in something the rep can check.
The second common mistake is over-enriching. Pulling 30 fields per contact sounds thorough and creates noise. Reps won’t read a three-page brief before a cold call. They’ll read a score and two sentences. Keep the writeback tight: ICP score, industry, company size, and one paragraph that explains the score. That’s what gets used.
What this means for your team
The math is straightforward. If your team spends 20 minutes per lead on manual research and handles 50 leads per week, that’s 1,000 minutes of research time. At 30-60 seconds per lead for the automated workflow, it drops to 25-50 minutes. The difference isn’t “slightly faster research.” It’s research time that effectively disappears as a cost.
The consistency gain matters as much as the time saving. Manual research quality depends on which rep does it, how much time they have, and how skilled they are at finding the right signals. Automated enrichment applies the same scoring logic to every lead. A lead that arrives Monday morning when the rep is fresh gets the same treatment as one that hits at 4pm on Friday.
For small teams where one or two people handle inbound, the consistency argument is even stronger. There’s no competing priority, no rep who does it thoroughly versus one who skips it when they’re busy. The brief is there, every time, before the rep looks at the record.
Frequently asked questions
How much does this cost to run per month?
At 5,000 leads per month, you’re looking at roughly $150-200 in API costs: People Data Labs at around $0.05 per enriched record, Perplexity at roughly $0.03 per research call, and Claude at under $0.01 per scoring request. n8n Cloud adds $20-50 depending on execution volume. Compare that to Clay’s Growth plan at $495/month for similar volume, or their Enterprise tier at $1,500+ for 20,000 leads. You own the logic and pay for the data.
What if People Data Labs doesn’t have data on my contacts?
PDL misses roughly 30-40% of records depending on your segment. Build a fallback node: if PDL returns no match, route to an Apollo or Clearbit HTTP request. The n8n workflow handles this with a conditional branch after the PDL node. For contacts that fail both, log the record to HubSpot with a task for manual review rather than skipping it entirely.
Do I need a HubSpot paid tier to set up the stage-change trigger?
The webhook trigger fires from a HubSpot Contact or Deal workflow, which requires at least Starter for contacts or Professional for deal-based workflows. If you’re on Free, you can use a form submission trigger or an n8n polling trigger instead. The enrichment logic is the same either way.
Can this work with Salesforce, Pipedrive, or another CRM?
Yes. The trigger pattern works wherever your CRM can fire a webhook or be polled by n8n. Replace the HubSpot nodes with the equivalent for your CRM. The enrichment, scoring, and routing logic is CRM-agnostic. You’ll need to remap the field writeback to match your CRM’s contact properties.
What fields should I write back to HubSpot?
At minimum: company size, industry, ICP score, and a one-paragraph brief as a note on the contact. If your routing depends on geography or tech stack, add those too. The goal is that when a rep opens the record, they see the score and the brief without having to do any research themselves.
— Stuart, Hotkey
Why AI Feels Underwhelming in Your Sales Process (and the 3 Workflows That Actually Deliver)
Most sales teams try AI on open-ended tasks and get generic results. Here are 3 narrow, trigger-based workflows that consistently save real time for B2B teams.
Read article →
HubSpot's AI Agents Now Charge Per Result. Here's What That Means for Buying vs. Building Sales AI.
HubSpot's Breeze agents now charge per outcome. Here's why that works inside one CRM, and where it breaks down elsewhere in your sales process.
Read article →
Claude Can Now Run Agents on a Schedule. What That Changes for a Small B2B Sales Team.
Claude's June 2026 scheduled agents run unattended on a cadence and reach your CRM. Here's what a small sales team can put on a schedule, and where a human still belongs.
Read article →